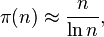Heterogeneous compute case study: image convolution filtering
이기종 컴퓨팅 적용
사례 : 이미지 컨볼루션 필터링
In a
previously published article, I offered a quick guide to writing OpenCL kernels for PowerVR Rogue
GPUs; this sets the scene for what follows next: a practical case study that
analyzes image convolution kernels written using OpenCL.
Many image processing tasks such as blurring,
sharpening and edge detection can be implemented by means of a convolution
between an image and a matrix of numbers (or kernel). The figure below
illustrates a 3×3 kernel that implements a smoothing filter, which replaces
each pixel value in an image with the mean average value of its neighbours
including itself.
예전에 나는 PowerVR Rogue GPU를 위한 a quick guide to writing OpenCL kernels 라는 글을 기고했었다. 여기에서 언급할 내용은 OpenCL로 작성된 이미지 컨볼루션 커널을 분석하는 실제 적용 사례에 대한 것이다.
Blurring, sharpening, edge detection 등과 같이 많은 이미지 처리 연산들은 하나의 이미지와 여러 개의 matrix 사이의 컨볼루션으로 정의되고 구현된다.(또는 커널 이라고도 한다). 아래 그림을 보면 3x3 커널이 보이고 여기서는 smoothing filter연산을 구현한 것이다. 이미지 내의 각각의 픽셀은 그 주위의 픽셀 값들의 평균 값으로 대체된다.
Kernel
convolution usually requires values from pixels outside of the image
boundaries. A variety of methods can be used to handle image edges, for example
by extending the nearest border pixels to provide values for
the convolutions (as shown above) or cropping pixels in the
output image that would require values beyond the edge of an input image, which
reduces the output image size.
커널 컨볼루션은 주로 이미지경계 밖의 외곽선의 픽셀 값을 필요로 한다. 이미지 경계선을 처리하기 위해 다양한 방법들이 사용되는데, 예를 들면 (위 그림처럼) 컨볼루션 연산을 위한 값을 가장 가까운 경계 픽셀로부터 단순히 확장해서 채우는 방법 또는 입력 이미지의 경계 부분의 값을 그대로 사용하고 결과 이미지의 외곽선 픽셀을 잘라내는 방법이 있을 수 있다. 후자의 경우 결과 이미지의 크기는 줄어든다.
The table below shows the algorithmic pseudo
code for this filter on the left along with a C implementation on the right. In
the C program, it is assumed that each pixel is represented by a 32-bit integer
comprising four 8-bit values for R, G, B and A; the macro MUL4 therefore
performs four separate multiplications, one for each of these 8-bit values.
아래 테이블은 위 예제를 코드로 표현한 것인데, 왼쪽은 간단한 알고리즘의 슈도 코드를, 오른쪽은 그에 대응하는 C 코드를 보여준다. C 프로그램에서 각각의 픽셀은 32비트 정수로 표현되며 각각 R, G, B, A(알파) 채널에 해당하는 색상을 8비트로 표현한다. 코드의 “MUL4” 매크로는 네 개의 분리된 곱 연산을 수행하며, 그 연산들은 각각 8비트 값에 대한 연산이다.
Convolution filter pseudo code
|
Convolution filter in C
|
|
void blur(int src[Gx][],int dst[Gx][],
char *weight)
{ int x, y, pixel, acc;
|
|
|
for each image row
in input image:
|
|
for each pixel in image row:
|
|
|
|
|
|
|
|
|
for each kernel row in kernel:
|
|
for each element in kernel row:
|
|
multiply element value corresponding to pixel value
|
pixel
= MUL4(src[y+j][x+i], weight[j+1][i+1], 16);
|
add result to accumulator
|
|
set output image pixel to accumulator
|
|
By using
the same approach as introduced in my previous article to extract the inner
compute kernel from the serial control flow (the outer two nested loops), and
applying the programming guidelines found here,
the following OpenCL kernel is produced.
예전 글에서 소개한 것과 같은 방식으로 순차적인 코드의 control flow를 아래와 같은 OpenCL 커널로 작성할 수 있다..
__attribute__((reqd_work_group_size(8, 4,
1)))
__kernel void blur(image2d_t src, image2d_t
dst, sampler_t s, float *weight)
{
int
x = get_global_id(0);
int
y = get_global_id(1);
float4 pixel = 0.0f;
for
(j=-1; j<=1; j++) {
for (i=-1; i<=1; i++)
pixel += read_imagef(src, (int2)(x+i,y+j), s) * weight[j+1][i+1];
}
write_imagef(dst, (int2)(x,y), pixel/9.f);
}
|
__attribute__((reqd_work_group_size(8, 4,
1)))
|
The statement sets the workgroup size at
compile-time to 32 (8x4). This restricts the host program to enqueuing
this kernel as a 2D range with an 8×4 configuration, but improves the
performance of the kernel when compiled.
이 명령줄에서 workgroup 크기는 컴파일 시에 32로 정해진다(8x4). 이는 호스트 프로그램이 8x4의 설정 값으로 커널을 2D range로 enqueue 하도록 제한한다. 하지만 일단 컴파일이 되면 커널의 성능은 증가한다.
__kernel void blur(image2d_t src, image2d_t
dst, sampler_t s, …
|
The function declaration specifies OpenCL
image parameters and a sampler for accessing image data from system memory. To
implement the border pixel behaviour in the above example, the host should
configure the sampler as clamp-to-nearest-border (not shown).
여기에 선언된 커널 함수는 OpenCL 이미지와 시스템 메모리로부터 이미지 데이터를 접근하기 위한 sampler를 파라미터로 선언한다. 경계 픽셀 영역을 고려하기 위해 호스트는 sampler를 clamp-to-nearest-border로 설정해야 한다.(여기선 안보이는데, 커널 함수 호출 시 파라미터에 넣는 sampler 이미지를 선언할 때 sampler state를 설정하는 부분이 있다. 다음 링크를 참고하라. 역자 주 https://www.khronos.org/registry/cl/sdk/1.0/docs/man/xhtml/sampler_t.html )
The statement defines a vector of four 32-bit
floating point values. The threads use floating-point arithmetic to perform the
convolution, which offers higher throughput compared to integer or character
data types.
이 명령줄은 4개의 32비트 floating 포인트 값에 대한 벡터를 정의한다.(4차원 벡터이다) 스레드는 컨볼루션을 수행하기 위해 floating-point 산술 연산을 사용하는데, floating-point를 쓰는 것이 정수나 문자열 데이터 타입에 비해 훨씬 빠른 연산 속도를 제공한다.
read_imagef(src, s, (int2)(x+i,y+j))
|
The statement causes the TPU to sample a
pixel from system memory into private memory, converting the constituent R, G,
B and A values into four 32-bit floating-point values and placing these into a
four-wide vector. This conversion is performed efficiently by the hardware,
requiring the multiprocessor to issue just a single instruction.
이 명령줄은 시스템 메모리로부터 픽셀 데이터를 읽어서 private memory 영역으로 복사를 하도록 TPU(Texture Processing Unit)를 사용한다. 이 때 R,G,B,A 값들을 4개의 32비트 floating-point 값으로 변환을 하고 4차원 벡터에 넣는다. 이 컨볼루션은 하드웨어에 의해 매우 빠르게 수행되며, 단 하나의 멀티프로세서 instruction 으로 수행된다.
write_imagef(dst, (int2)(x,y), pixel/9.f);
|
The statement writes a (normalized) output
pixel value back to system memory.
이 명령줄은 결과 픽셀 값들을 시스템 메모리에 쓰는 역할을 한다.
Caching
frequently-used data in the common store
자주 사용되는 데이터를 common store에 캐쉬하기
In the example in the previous section, all
work-items operate independently of one another, each work-item independently
sampling nine input pixels to calculate one output pixel. Overall the kernel
has a fairly low arithmetic intensity (i.e. a low ratio of
multiply-and-accumulate operations to memory sampling operations), which can
lead to low performance.
이전에 보여준 예제에서 모든 work-item들은 독립적으로 수행하고, 각각의 work-item들은 하나의 결과 픽셀을 내놓기 위해 9개의 입력 픽셀을 독립적으로 샘플링한다. 이는 커널 전반적으로 동등하게 낮은 산술 집적도를 갖는다. (메모리 샘플링 연산에 비해 multiply-and-accumulate 연산의 비율이 낮다.) 당연한 이야기겠지만 낮은 산술 집적도는 낮은 성능을 야기시킨다.
For a workgroup size of 32, each workgroup
performs a total of 288 (9×32) sampling operations. However, as show below,
adjacent work-items use six of the same overlapping pixels from the input
image.
workgroup 사이즈를 32로 정할 때, 각각의 workgroup은 총 288(9x32)번의 샘플링 연산을 수행한다. 하지만 아래에서 보여지듯, 두 개의 인접한 work-item들 사이에 동일한 입력 이미지 안에서 6개의 픽셀 영역이 겹쳐진다.
The common
store is a fast on-chip memory that you can use to optimize access to
frequently-used data, and also to share data between work-items in a workgroup,
in this case enabling reduction of the number of sampling operations performed
by a workgroup. A typical programming pattern is to stage data from system
memory into common store by having each work-item in a workgroup:
Common store는 빠른 on-chip 메모리로서 자주 사용되는 데이터에 대한 접근을 최적화 할 수 있게 한다. 또한 workgroup 안의 work-item 들 간의 데이터 공유 또한 가능하게 한다. 이 예시에서는 workgroup에 의해 수행되는 sampling 연산의 수를 줄인다. 일반적인 프로그래밍 패턴은 하나의 workgroup 안에 각각의 work-item을 갖도록 만들어서 시스템 메모리로부터 common store로 데이터를 위치시킨다.
아래에 그 방법을 순서대로 설명하였다.
·
Load data from global
memory to local memory.
먼저 Global memory로부터 local memory로 데이터를 읽어
들인다.
·
Synchronize with all
other work-items in the workgroup, ensuring all work-items block until all
memory reads have completed.
·
모든 work-item들이 모든 메모리
접근이 끝날 때까지 block되도록 Workgroup 내
모든 work-item들을 동기화 한다.
·
Process the data in local
memory.
Local memory에 있는 데이터를 처리한다.
·
Synchronize with all
other work-items in the workgroup, ensuring all work-items finish writing their
results to local memory.
모든 work-item들이 결과를 local memory에 쓰도록 Workgroup 내의 모든 work-item들을 동기화 한다.
·
Write the results back to
global memory.
결과를 global memory로 돌려준다.
The example program below is a refinement of
the previous program, rewritten to use local memory to reduce the number of
sampling operations to system memory.
아래의 프로그램 예제는 앞의 예제 프로그램에서 시스템 메모리에 대한 sampling 연산의 수를 줄이도록 local memory를 사용하도록 수정한 것이다.
__attribute__((reqd_work_group_size(8, 4,
1)))
__kernel void blur (image2d_t src,
image2d_t dst, sampler_t s, float *weight)
{
int2 gid = (int2)(get_group(id(0)*8, get_group_id(1)*4);
int2 lid = (int2)(get_local_id(0), get_local_id(1));
float4 pixel = 0.0f;
__local float4 rgb[10][6];
prefetch_texture_samples_8x4(src, sampler, rgb, gid, lid);
for
(j=-1; j<=1; j++) {
for (i=-1; i<=1; i++)
pixel += rgb[lid.x+1+i][lid.y+1+i]) *
weight[j+1][i+1]);
}
write_imagef(dst, (int2)(x, y), pixel/9.f);
}
void prefetch_texture_samples_8x4(image2d_t
src, sampler_t s, __local float4 rgb [10][6], int2 gid, int2 lid)
{
if
(lid.x == 0) {
// work-item 1 fetches all 60 rgb samples
for (int i=-1; i<9; i++) {
for (int j=-1; j<5; j++)
rgb[i+1][j+1] = read_imagef(src, s,
gid+(int2)(i, j));
}
}
barrier(CLK_LOCAL_MEM_FENCE);
}
|
__local float4 rgb[10][6];
|
The statement declares a local array, which
is allocated in the common store.
이 명령줄은 local 메모리 영역에 배열을 선언한다. Local 메모리에 선언된 배열은 common store에 할당된다.
The kernel first calls the function
커널은 먼저 아래 함수를 호출한다.
void prefetch_texture_samples_8x4( …
|
In this function, all work-items in a
work-group first test their local ID together, and work-item 0 samples data
from memory into the common store; all work-items then synchronize on a
barrier. This synchronization operation is necessary to prevent the other
work-items from attempting to read uninitialized data from the common-store. In
the main kernel, calls to read_imagef are replaced by reads from the local
memory array rgb.
이 함수에서 workgroup 내의 모든 work-item들은 제일 먼저 local ID를 테스트 한다. 그리고 work-item 0은 데이터를 메모리로부터 common store로 샘플링한다. 그 다음 모든 work-item 들은 barrier 연산에서 동기화가 된다. 이 동기화 연산은 common-store에 초기화 되지 않은 데이터를 읽으려는 다른 work-item들의 작업을 막는다. 메인 커널에서는 read_imagef()를 호출하던 것이 local memory 배열인 ‘rgb’로부터 데이터를 읽는 것으로 대체되었다.
In this optimized program each work-group
performs a total of 60 sample operations, all during initialization, compared
to the 288 in-line sampling operations performed in the original program. This
reduction in memory bandwidth can significantly improve performance.
이 최적화된 프로그램은, 기존 프로그램에서 모든 초기화 과정에서 288 개의 in-line 샘플링 연산을 수행하던 것을 각각의 workgroup이 단지 총 60개의 샘플 연상을 수행하도록 수정된 것이다.
The prefetch function can be further improved
so that instead of a single work-item fetching 60 samples in sequence, 30
work-items each fetch two samples in sequence. The following example shows one
way in which this can be implemented.
prefetch 함수를 통해, 60개의 단일 work-item 에 대한 샘플링이 순차적으로 실행되는 대신에 30개의 work-itme들이 각각 두 개의 샘플 연산을 순서대로 처리함으로써 성능을 개선할 수 있다. 아래의 예제는 이를 구현한 것을 보여준다.
inline void
prefetch_8x4_optimized(image2d_t src, sampler_t s, __local float4 rgb[10][6])
{
//
Coord of wi0 in NRDange
int2 wi0Coord = (int2)(get_group_id(0)*8, get_group_id(1)*4);
//
2D to 1D address (from 8x4 to 32x1)
int
flatLocal = get_local_id(1)*8 + get_local_id(0);
//
Only first 30 work-items load, each loads 2 values in sequence
if (flatLocal < 30)
{
/* Convert from flatLocal
1D id to 2D, 10x3 */
int i = flatLocal % 10;
// Width
int j = flatLocal / 10;
// Height
/* 30 work items reads 10x3 values,
* values 0-9, 10-19, 20-29 from 10x6 - top half
*/
rgb[j][i] =
read_imagef(src, s, (int2)(wi0Coord.x + i - 1, wi0Coord.y + j - 1));
/* 30 work iteams reads 10x3 values,
* values 30-39, 40-49, 50-59 from 10x6 - bottom half
*/
rgb[j + 3][i] = read_imagef(src, s,
(int2)(wi0Coord.x + i - 1, wi0Coord.y + j + 3 - 1));
}
barrier(CLK_LOCAL_MEM_FENCE);
}
|
In the best case, work-items can fetch data
from the common store in a single cycle. In practice, however, a number of
conditions must be met to achieve this efficiency.
여기에서 work-item들은 단일 사이클 내에서 common store 로부터 데이터를 fetch 한다. 그러나 이를 달성하기 위해서는 실제로는 수많은 조건들이 따른다.
Computer vision is what we’ll be focusing on
for the next section of our heterogeneous compute series; stay tuned for an
overview of how you build a computer vision platform for mobile and embedded
devices.
다음에는 이기종 컴퓨팅 시리즈 섹션에서 컴퓨터 비전에 대한 내용에 초점을 맞춰 다루도록 하겠다. 모바일과 임베디드 디바이스에서 어떻게 컴퓨터 비전 플랫폼이 구성되고 최적화를 하는지 설명할 것이다.